
The eBPF - 2
In this blog, we will continue with tracing. We'll aim to get a basic understanding of:
How processes work
Exit codes
Forking of processes
Exit tracepoints (of the execve() syscall)
Recommended reading: If you've not read the first article, please read eBPF-1.
A bit about processes and forking

When you run a command in a terminal, bash will first call the
fork()system call.This creates a new child process that is almost an exact copy of the original bash process in which you typed your command.
In the child process, (after the
fork()), bash calls one of the exec*() functions - in this scenario -execve()to replace its process image with that of the command that you just ran.In the context of the above screenshot:
(on the left terminal) We echoed our bash (parent) process id. Then we ran a few commands - we can see how the pids of the process that spawn are different from the original parent.
The pids on the right are children of the original process. Once the commands finished running, they returned control back to the original parent process.
Let's contrast this and spawn a new process without forking. We'll need to write a little code for this.
#include <stdio.h>
#include <unistd.h>
int main(void)
{
char *margs[] = {"/bin/id", NULL, NULL, NULL, NULL };
int rc = execve(margs[0], margs, NULL);
printf("If all goes well, we don't see this %d\n", rc);
return rc;
}
Let's compile this
gcc exec_test.c -o exec and run the code.

In the above snapshot, you can see that the 'exec_test' process, and the /bin/id process have the same pid - 8241.
Now let's contrast the above scenario, by modifying this code to fork before running a command.
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main(void)
{
int pid = fork();
int rc = 0;
if (pid ==0) {
printf("I am the child\n");
char *margs[] = {"/bin/id", NULL, NULL, NULL, NULL };
rc = execve(margs[0], margs, NULL);
printf("We should not see this %d\n", rc);
} else {
printf("I am the parent\n");
}
return rc;
}
The above code should be mostly self-explanatory. The part about pid == 0 can be explained using the man 2 fork page. A screenshot of the relevant portion of the man page is below.

Let's compile this
gcc fork_exec_test.c -o fexe and run the code.
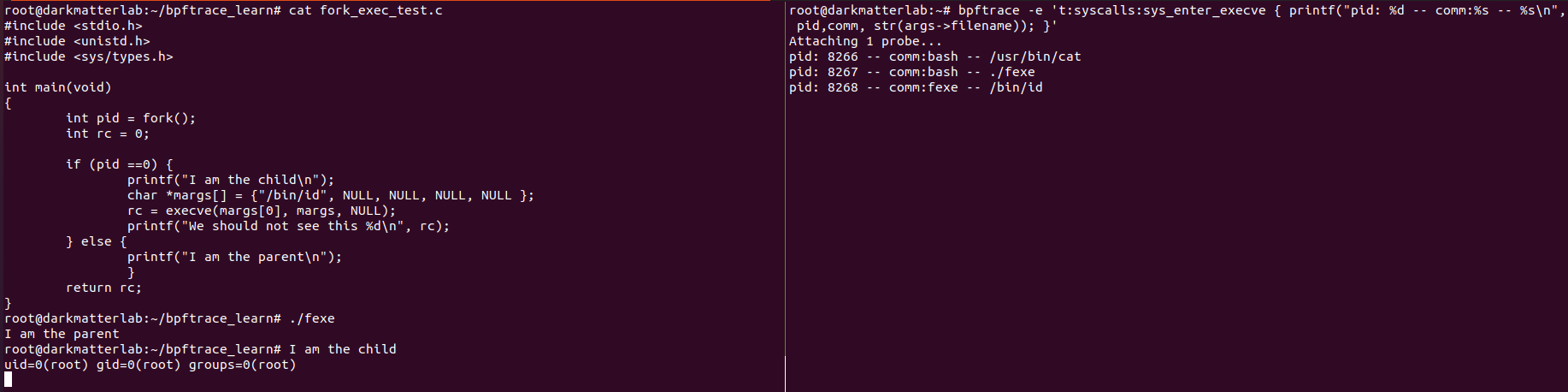
We can see that the fexe process forked and the /bin/id is run under a new process id .i.e 8276 and 8268 respectively.
What is a process image?
A process image is a snapshot of everything that is needed to run or resume a process. This includes:
The code (or text) of the program.
The current activity represented as the program counter.
The processor's registers.
The program stack which contains local variables.
Memory which includes global variables.
A list of open files or I/O ports.
The program's data, which consists of static and dynamic variables.
In the above bits of C code, do you notice that some printf statements state something to the tune of 'We shouldn't see this'? That is because, the execve() syscall does not really 'exit' in a traditional sense - unless there is some exception, and the exit code is something other than 0. Go ahead, and put the name of a non-existent binary, compile, and run the programs again. You'll see something like the screenshot below. We get the return value (rc) in the entry point trace.

This brings us to the question - how do we get the exit / return code value if the execve() is successful?
The answer lies in the exit point trace. So sys_enter_execve and sys_exit_execve represent a couple of separate moments. To understand this better, take a look at the kernel source code. https://elixir.bootlin.com/linux/v5.15.126/source/fs/exec.c#L2090 - I'm using the 5.15 kernel for this demonstration - please pick your kernel version appropriately.
SYSCALL_DEFINE3(execve,
const char __user *, filename,
const char __user *const __user *, argv,
const char __user *const __user *, envp)
{
return do_execve(getname(filename), argv, envp);
}
The 'exit' tracepoint will grab what happens at the return, or after the return. We can understand this better by looking at the format of the exit tracepoint (in contrast to the entry tracepoint that we looked at in the last article)
root@darkmatterlab:/sys/kernel/debug/tracing/events/syscalls# cat sys_exit_execve/format
name: sys_exit_execve
ID: 715
format:
field:unsigned short common_type; offset:0; size:2; signed:0;
field:unsigned char common_flags; offset:2; size:1; signed:0;
field:unsigned char common_preempt_count; offset:3; size:1; signed:0;
field:int common_pid; offset:4; size:4; signed:1;
field:int __syscall_nr; offset:8; size:4; signed:1;
field:long ret; offset:16; size:8; signed:1;
print fmt: "0x%lx", REC->ret
We can see the 'ret' variable here. If we want to get the ret value in a success scenario (i.e execve() executes without any issues), then we can use this tracepoint in our bpftrace. Let's construct the statement
bpftrace -e 't:syscalls:sys_enter_execve { printf("ENTER pid: %d -- comm:%s -- %s\n", pid,comm, str(args->filename)); } t:syscalls:sys_exit_execve { printf("EXIT pid: %d -- ret: %d --comm %s\n",pid, args->ret,comm); }'
Notice how we didn't need to use the 'str' function around the 'ret' variable - because it is not a string type. If we run this, it looks something like

Notice that now we are attaching 2 probes, since we are tracing both, the entry and exit points of the execve() syscall. You can also see that on the left, we see the error is -1, and on the right, the error is -2. To find the explanation for that, look at man 2 execve. The relevant portion is in the screenshot below.

We can look at man 3 errno to understand what error code -2 means (which is the actual error code after being set appropriately).
ENOENT 2 No such file or directory
Read the man pages to understand more about these concepts. Play around with your own combinations. Write some more C code and fork process, create errors and break things. Look at your trace.
As a last step, we can make this whole bpftrace command a bit neater by putting the trace scripts in a fill. It's cumbersome to write our bpfcode after the -e flag, so let's put that neatly into a file, and use bpftrace to call that file. Create a new file called bpf_examples.bpf and put the following code in it.
t:syscalls:sys_enter_execve { printf("ENTER pid: %d -- comm:%s -- %s\n", pid,comm, str(args->filename)); }
t:syscalls:sys_exit_execve { printf("EXIT pid: %d -- ret: %d --comm %s\n",pid, args->ret,comm); }
Now simply run # bpftrace bpf_examples.bpf and that should do the trick
Conclusion
In conclusion, we explored around quite a bit in this post. Although we effectively only used the exit tracepoint of execve(), we learned a couple of new things about processes, forking, pids and exit codes. Strong basics are what make great engineers.


